品牌危机在评论区爆发,你的团队能在30分钟内响应吗?
周一早上,你打开 Instagram 后台,准备按惯例看一眼数据、回几条评论。
然后你看到了那条帖子。
一条普通的产品投诉,发布于三天前。现在,它有 312 条回复,点赞数破千,截图已经扩散到 X 的热门话题,TikTok 上出现了至少 6 条跟风视频,其中一条播放量 47 万。你的品牌名正在被批量转发,附带的标签是「#避雷」和「#品牌黑料」。
而这一切,发生在你完全不知情的三天里。

三天前的那条评论,你今天才看到
这个场景不是假设,它每天都在真实发生。
一个拥有十万粉丝的美妆品牌,因为一批产品出现色差问题,某位用户在 Instagram 贴文下留言投诉。这条评论本身措辞激烈,但在发布后的头几个小时内,并没有引起太大波澜。品牌团队当时正在赶下一周的内容排期,那条贴文已经发出三天,按照惯例不在重点监控范围内。
没有人看到那条评论。
第一天,5 个人点了「赞同」,两个人跟帖说「我也遇到了同款问题」。第二天,一个拥有 8 万粉丝的博主在 Story 里截图转发,加了一句「大家注意一下」。到了第三天,话题已经蔓延出去了——X 上有人用品牌名搜索,发现这条讨论,写了一条「避雷长文」;TikTok 上有人把截图做成视频,配上戏剧性的背景音乐,单条播放量超过 40 万。
你在第四天早上发现了这一切。
此刻,你能做什么?
在舆论场里,你的品牌已经成了「那个有色差问题还不回应的品牌」。你想发声明,但声明下面立刻会有人说「现在才出来,三天前去哪儿了」。你想道歉,但道歉内容会被人反复截图、逐句解读,稍有措辞不当就是第二轮舆情。你想删评,但删评会被拍下来,成为「品牌删差评掩盖问题」的新素材。
每一条路都在走向更深的泥潭。
这不是团队能力的问题,也不是公关话术够不够好的问题。根本问题只有一个:你们发现得太晚了。
危机的时钟,从第一条差评就开始倒计时
很多品牌运营团队有一个共同的误区:认为品牌危机是「突然爆发」的。其实不是。危机在评论区里是一条一条积累的,它有完整的传播路径,也有明确的时间窗口——而这个窗口,通常只有 24 到 48 小时。
危机传播的四个阶段
社媒危机的传播遵循一个相对固定的节奏,理解这个节奏,才能找到正确的介入时机。
第一阶段(0-6小时):火苗期。 负面评论刚刚出现,传播范围有限,通常只在原帖评论区内发酵。这是介入成本最低的时间窗口。一条及时、真诚的品牌回复,可以在这个阶段直接熄灭火苗——用户感受到被重视,跟风批评的动力大幅降低。研究数据显示,品牌在 1 小时内响应的情况下,超过 70% 的投诉用户愿意给出第二次机会;而超过 24 小时才响应时,这一比例骤降至不足 20%。
第二阶段(6-24小时):扩散期。 原帖评论量持续增长,具有传播影响力的用户开始注意到这条讨论,并选择在自己的账号上转发或提及。此时话题仍主要集中在单一平台,但已经开始向外渗透。在这个阶段介入,仍然有效,但需要更正式的声明和更清晰的解决方案承诺。
第三阶段(24-48小时):失控期。 话题已跨平台传播,不同平台的讨论相互引用、互相强化。媒体可能开始关注,搜索引擎上关于品牌的负面内容开始上位。在这个阶段,品牌的任何单一响应都难以覆盖全部舆论场,公关成本成倍增加。
第四阶段(48小时以上):沉淀期。 热度自然衰减,但负面内容已经形成固化记忆。搜索品牌名时,相关词条中出现负面联想;新用户在购买决策时会看到这些历史讨论。品牌受到的伤害从短期情绪反应转变为长期信任损耗。
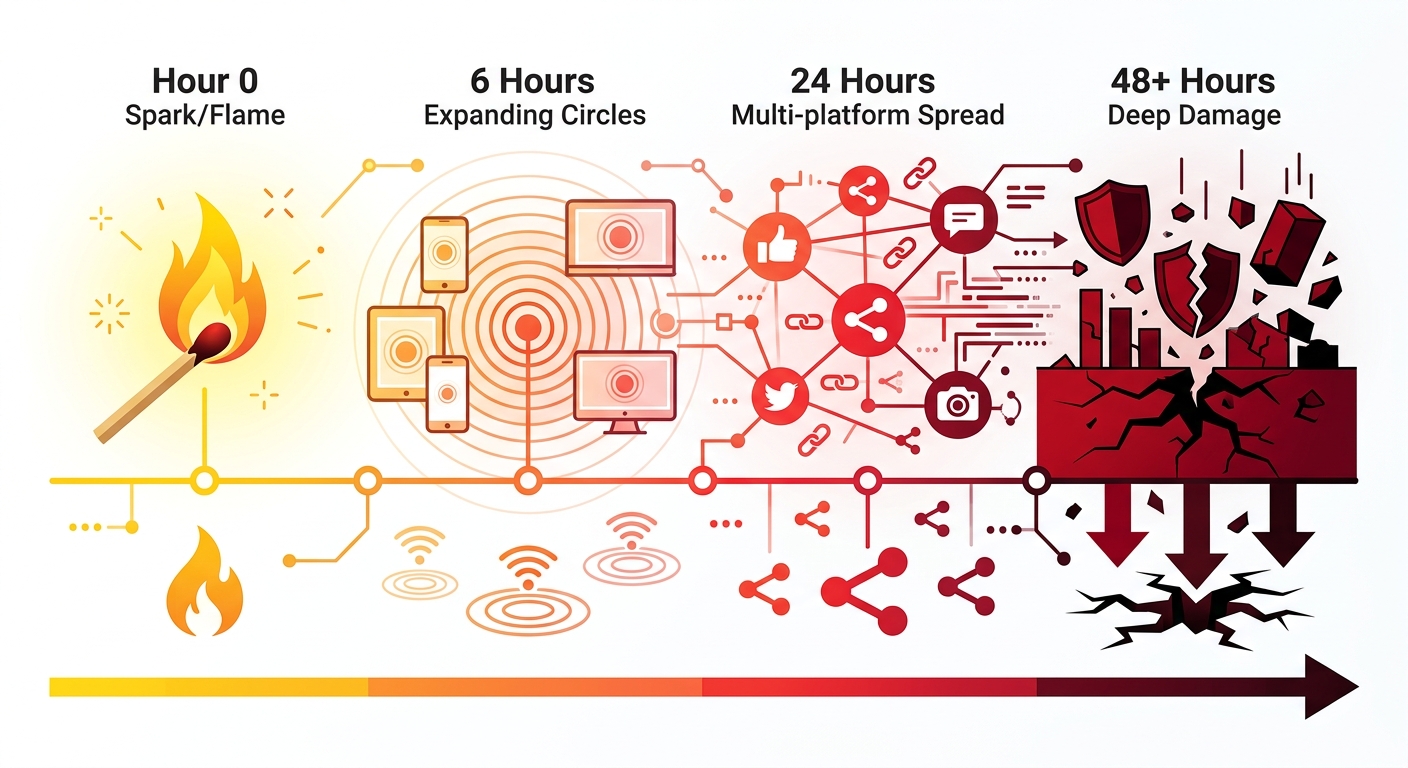
这个时钟,从第一条差评出现的那一刻就开始倒计时了。
多平台监控的死角,是危机最喜欢藏身的地方
现在的品牌运营,几乎无一例外地同时运营多个平台。Instagram 发产品图,Facebook 维护社群,X 做实时互动,TikTok 投短视频,小红书和 YouTube 也都有布局。每个平台都有各自的后台,各自的通知逻辑,各自的评论管理界面。
对于一个 1-3 人的内容团队来说,这意味着什么?
意味着你每天需要手动巡检至少 4-5 个平台的评论区。意味着你可能因为正在处理 Instagram 的评论,而错过了 Facebook 上同一时间段内爆发的负面讨论。意味着你没有任何机制可以在第一时间告诉你「有问题出现了」——你只能依靠定时手动巡查,而这个巡查频率,远远跟不上危机传播的速度。
更致命的是,危机往往在非工作时间爆发。周五下午六点,一条投诉评论开始发酵;周六早上你才想起来看后台。这 14 个小时,足够一个话题从火苗烧成熊熊大火。
Facebook 评论管理、Instagram 评论管理、X 关键词监控、TikTok 评论管理——每一个平台都是一个独立的监控盲区,而当危机跨平台蔓延时,这些盲区会叠加成一个巨大的漏洞。
为什么「看到了但没当回事」同样致命
有时候,危机不是因为没被发现,而是因为被低估了。
一条有点激进的投诉评论,运营同学看了一眼,觉得「这就是个别用户情绪发泄,不用理」。但这条评论下面,已经有 3 个人表示认同。6 小时后,有 15 个人跟帖。到你下班回到家,已经有 80 条回复了。
问题不是运营同学判断错了,而是他当时没有足够的信息来做判断。他看到的是一条评论,他不知道这条评论正在以什么速度获得共鸣,他不知道原帖作者有多少粉丝,他不知道这个话题有没有在其他平台同步扩散。
孤立的信息无法支撑准确的危机判断。 这是人工监控的结构性缺陷,不是个人失误。
在危机爆发之前,你需要一套预警机制
让我们不再讨论「如果危机已经爆发该怎么办」。那是被动的,是补救的,是代价高昂的。
真正有效的危机管理,从建立预警机制开始——在火苗还没烧起来之前,就把它找出来、扑灭它。
第一步:关键词监控,把危机词汇表变成你的预警网
危机监控的核心,是关键词体系的建立。你需要把可能引发品牌危机的词汇全部列出来,作为持续监控的触发条件。
这个词汇表应该覆盖三类内容:品牌词(品牌名、产品名、官方账号名)、问题词(质量问题、退款纠纷、客服投诉相关词汇)、情绪词(「避雷」「踩雷」「不推荐」「差评」「维权」等负面情绪词)。
关键词体系一旦建立,就需要实时运行,而不是定时扫描。因为危机发展的速度是以小时计算的,每隔几小时才触发一次扫描的系统,根本跟不上舆情演变的节奏。
社媒监听 是整个预警机制的基础设施。SocialEcho 的实时关键词监控支持 1000+ 自定义关键词,覆盖品牌名、产品词和危机词库,一旦相关内容出现,系统立即捕捉——不需要你手动巡查,不会因为时区或工作时间产生监控空白。
第二步:情绪波动预警,让数字告诉你「现在有问题」
监控到关键词只是第一步。更关键的问题是:这条内容是偶发的个人抱怨,还是正在形成规模的负面舆论?
这两种情况需要完全不同的响应策略。前者可以直接私信处理,后者需要立即启动危机响应流程。而这个判断,靠人工实时跟踪几乎无法实现——你不可能在几分钟内就判断出一条评论的传播势头。
情绪波动预警的价值在这里体现出来。当某个关键词在短时间内讨论量突然上升,或者相关内容的情绪倾向从中性变成负面集中,系统会立即触发提醒。这个提醒不是「有人提到了你的品牌」,而是「某个话题正在异常发酵,你需要现在去看一眼」。
SocialEcho 的 AI 情感分析模块可以自动判断每条相关讨论是正面、负面还是中性,准确率 95%+。结合情绪波动预警,你获得的不再是孤立的关键词命中,而是一张持续更新的舆情热度地图——让你在危机升温的第一时间就知道,而不是在它已经失控之后。
第三步:跨平台统一收口,把分散的战场变成一个指挥台
当你意识到危机正在扩散时,你面临的第一个实操难题往往不是「说什么」,而是「怎么同时看到所有地方正在发生什么」。
Instagram 评论区在炸,Facebook 私信在涌进来,X 上的话题在蔓延,TikTok 视频下面评论满了——你要同时打开几个后台?用什么顺序处理?哪些评论需要优先回复?
这个碎片化的信息状态,是危机响应最大的效率杀手。在你来回切换平台的时候,时间在流逝,舆情在发酵,而你的响应速度永远追不上传播速度。
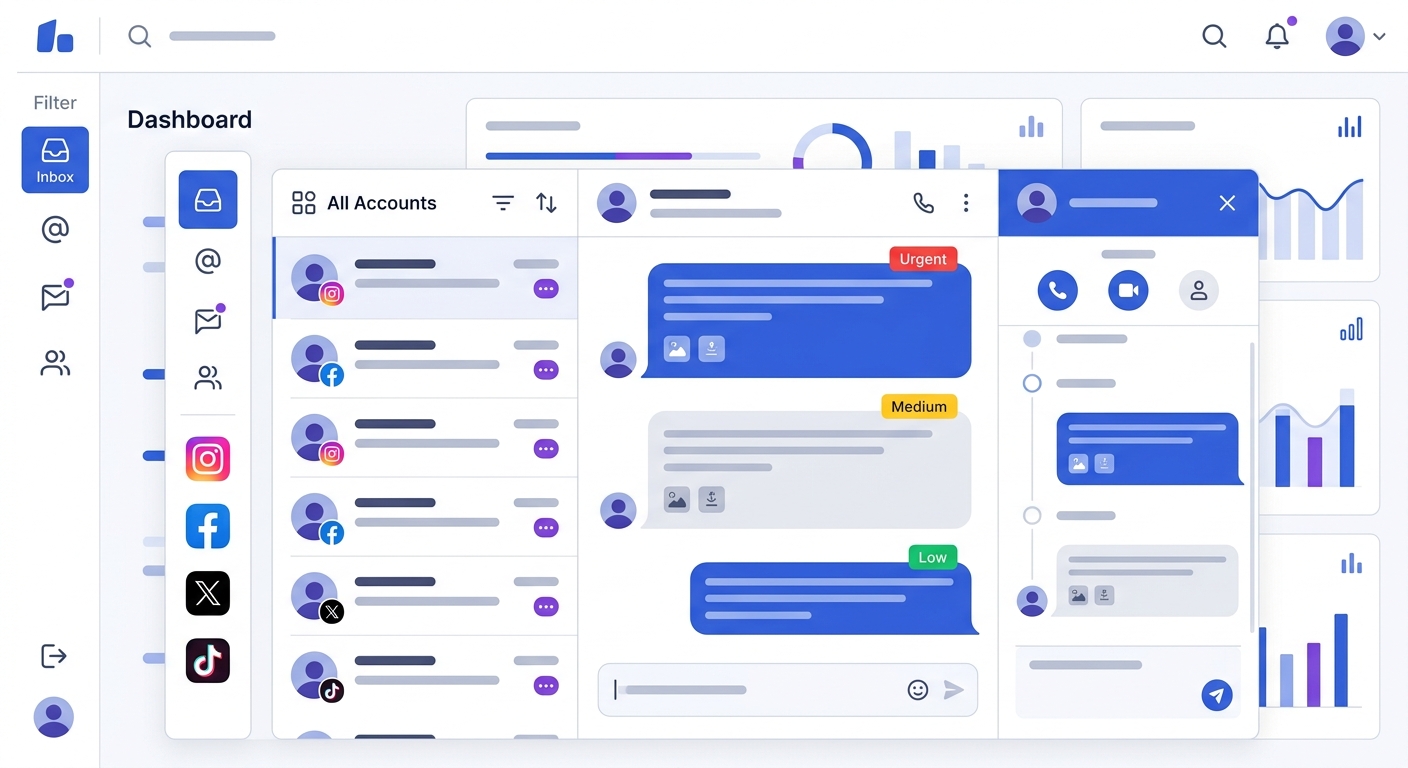
互动管理 解决的是这个问题。SocialEcho 的自动化收件箱将多平台评论和私信统一汇入一个界面,你不需要切换后台,就能看到所有平台的最新动态,按紧急程度排序,集中处理。一个人,一个屏幕,全平台信息尽收眼底。
这不只是「方便」,在危机响应中,这是生死线:30 分钟内能否完成全平台巡查并给出第一条官方回应,直接决定了这次危机的走向。
第四步:24/7 覆盖,让监控不因时间而中断
危机不看工作日,不看上下班时间。
很多品牌运营团队的危机,恰恰爆发在周末和节假日。这不是巧合——用户有更多时间刷社媒,有更多时间写评论、看讨论、参与围观。而品牌团队的监控密度,在这些时间段往往是最低的。
有效的预警机制必须是 24/7 运行的。SocialEcho 的监控系统全天候实时工作,即使在凌晨三点,一旦品牌相关的负面讨论触发情绪预警阈值,系统就会立刻发送提醒。你的团队不需要全天守在屏幕前,但你们需要确保,当真正的危机信号出现时,有人能在最短时间内看到并响应。
品牌危机响应的黄金 30 分钟
我们来把上述机制整合成一个具体的操作框架。一旦预警系统触发,你的团队应该在 30 分钟内完成以下动作:
0-5分钟:定性。 查看触发预警的原始内容,判断问题类型(质量投诉/服务纠纷/谣言/恶意攻击),评估发酵程度(评论数量、情绪倾向、是否跨平台)。
5-15分钟:收口。 通过统一收件箱快速扫描所有平台,确认危机扩散范围。重点关注原帖评论区、品牌相关话题标签、高粉丝量账号的转发情况。
15-25分钟:响应。 根据定性结果,选择响应策略。若为真实质量问题,在原帖下发布官方回复,承认问题、表达歉意、告知处理流程;若为误解或谣言,发布澄清内容,语气平和,配合证据;若为个别用户投诉,私信联系处理,同时在评论区给出简短公开回应表示关注。
25-30分钟:升级判断。 如果危机已经跨平台扩散,且核心话题涉及产品安全或重大品牌形象问题,立即升级至管理层,启动正式公关流程。
这个流程的前提,是预警系统在危机早期就发出了信号。没有这个前提,一切都是亡羊补牢。
SocialEcho 是什么,它适合哪类团队
对于正在读这篇文章的品牌运营团队,我想在这里直接说明:SocialEcho 是一款专为多平台社媒运营团队设计的社媒管理与监听工具,尤其适合企业内部 1-5 人规模的社媒团队。
它解决的核心痛点,正是本文一直在描述的:多平台分散监控带来的响应滞后,以及人工巡查无法覆盖的时间盲区。
通过 社媒监听 模块,SocialEcho 实现对品牌相关关键词的 24/7 实时捕捉,结合 AI 情感分析和情绪波动预警,让品牌团队在危机早期就获得预警信号——而不是在舆论失控之后。
通过 互动管理 模块,SocialEcho 将 Facebook、Instagram、X、TikTok 等多平台的评论和私信统一汇入一个操作界面,让小团队能够以最高效率完成跨平台响应——这正是黄金 30 分钟响应框架得以落地的基础设施支撑。
它不是一套复杂的企业级舆情系统,不需要专职 IT 团队部署和维护。它的设计目标,就是让一个普通的品牌运营专员,能够在日常工作流中完成专业级别的社媒危机预警与响应。
写在最后:危机不是你的敌人,「不知道」才是
品牌在社媒上遇到投诉和负面讨论,这件事本身并不致命。用户有情绪,会有人抱怨,偶尔会有差评引发更多讨论——这是正常的社媒生态,任何品牌都无法完全避免。
真正让危机演变成灾难的,是信息不对称:用户已经知道了,讨论已经扩散了,舆论已经定性了——而品牌团队还不知道发生了什么。
这种信息不对称,不是因为团队不努力,不是因为平台太多管不过来,而是因为没有一套系统在持续盯着那些角落,替你做那件「永远不可能靠人工完成」的事:全天候、跨平台、实时捕捉每一个可能演变成危机的信号。
那条三天前的评论,本来可以在 6 小时内被发现,在 1 小时内得到官方回应,在 24 小时内妥善处理,在整个事件成为话题之前就已经解决。
那个本来可以「30分钟内响应」的危机,因为没有预警机制,变成了需要花三周时间才能修复的品牌信任危机。
区别只在于:你的系统,有没有在第一时间告诉你。
相关阅读:
- Facebook 评论管理 — 如何管理 Facebook 上的用户评论与互动
- Instagram 评论管理 — Instagram 评论区的统一管理方案
- X 关键词监控 — 实时追踪 X 平台上的品牌相关讨论
- TikTok 评论管理 — TikTok 评论区的批量处理与预警
- 社媒监听 — 多平台关键词监控与情绪分析
- 互动管理 — 跨平台评论与私信统一收件箱